
Unleash the power of Robots Meta tags and take control of search engine crawlers with this comprehensive guide.

Image courtesy of via DALL-E 3
Table of Contents
Introduction to Robots Meta Tags
Robots meta tags play a crucial role in determining how search engines interact with and index web pages. These tags provide instructions to search engine crawlers, informing them about what content can be accessed and how it should be handled. Understanding robots meta tags is essential for website owners to control the visibility of their pages in search engine results.
What Are Robots Meta Tags?
Robots meta tags are snippets of code placed within the HTML of a webpage to communicate with search engine crawlers. These tags tell the crawlers whether specific pages should be indexed or not, and if they should follow the links on those pages. Essentially, robots meta tags act as a set of guidelines for search engines on how to interact with a website’s content.
Why Are They Important?
Robots meta tags are crucial for ensuring that search engines read and interpret web pages correctly. By using these tags, website owners can control which pages are included in search results and which are excluded. This helps in optimizing the visibility of important content and prevents unnecessary or sensitive information from being indexed by search engines.
Basic Robots Meta Tag Syntax
Writing a robots meta tag is a simple process that involves using basic HTML code. To create a robots meta tag, you need to include the following snippet within the <head> section of your webpage:
<meta name="robots" content="directive1, directive2">
In this code, you can replace directive1, directive2 with the specific directives you want to apply to your webpage.
Placing the Tag in the HTML
Once you have written your robots meta tag using the proper syntax, you need to place it in the HTML code of your webpage. Make sure to insert the tag within the <head> section of your HTML document. This placement ensures that search engine crawlers can easily access and interpret the directives you have set for your webpage.
Common Robots Meta Tag Directives
Index and noindex are common directives used in robots meta tags to control whether search engines can include a webpage in their index. When you want a webpage to appear in search results, you use the ‘index’ directive. On the other hand, if you don’t want a page to show up in search results, you use the ‘noindex’ directive.
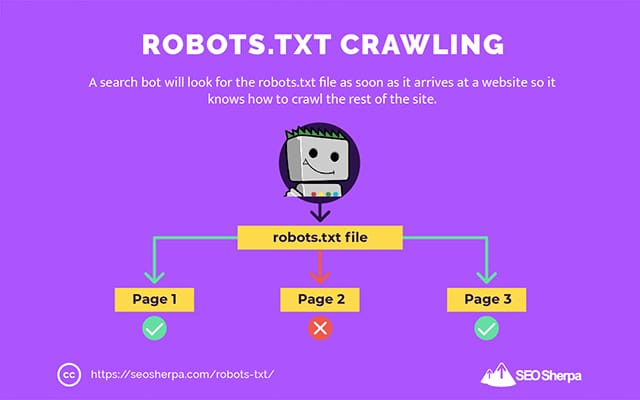
Image courtesy of seosherpa.com via Google Images
Follow and Nofollow
Follow and nofollow directives determine if search engine crawlers can follow links on a webpage. If you want search engines to follow the links on a page, you use the ‘follow’ directive. Conversely, the ‘nofollow’ directive instructs search engines not to follow those links.
By using these directives in robots meta tags, website owners have more control over how search engines crawl and index their content.
Advanced Robots Meta Tag Directives
One advanced directive you can use in robots meta tags is the ‘noarchive’ directive. This directive tells search engines not to store a cached copy of your webpage. When you use ‘noarchive’, search engines won’t be able to display a cached version of your page to users. This can be useful if you have content that is time-sensitive or if you want to retain control over how your content is accessed.
Nocache
Another advanced directive is ‘nocache’. When you include the ‘nocache’ directive in your robots meta tags, you are telling search engines not to store a temporary copy of your webpage. This can be beneficial if you have dynamic content on your site that changes frequently or if you don’t want search engines to display outdated information to users. By using ‘nocache’, you ensure that search engine crawlers fetch the most up-to-date version of your webpage every time they visit.
When to Use Robots Meta Tags
Have you ever searched for something online and found multiple websites with the exact same information? That’s called duplicate content, and it can confuse search engines. Robots meta tags can help prevent this issue by telling search engine crawlers whether a particular page should be indexed (included in search results) or not. By using the ‘noindex’ directive in robots meta tags, website owners can ensure that duplicate content doesn’t harm their site’s search engine rankings.

Image courtesy of thegray.company via Google Images
Managing Search Engine Load
Search engine crawlers are like little internet robots that constantly visit web pages to gather information. Sometimes, websites can get overwhelmed by the number of crawlers trying to access their pages all at once. Robots meta tags can come to the rescue by using the ‘crawl-delay’ directive, which instructs search engine bots to take a break between accessing different parts of a website. This helps manage the load on a website’s server and ensures that all visitors, including search engine crawlers, have a smoother browsing experience.
Testing and Verifying Robots Meta Tags
Once you have added robots meta tags to your website, it’s essential to ensure that they are working correctly. Luckily, there are various tools available to help you test and verify your robots meta tags. These tools can provide valuable insights into how search engine crawlers interpret your directives.
Common Mistakes
While working with robots meta tags, it’s important to be aware of some common mistakes that can affect their effectiveness. One common error is incorrectly formatting the directives within the tag, which can lead to search engines misinterpreting your instructions. Another mistake is forgetting to include the robots meta tag on all relevant pages of your website, leaving some pages open to be crawled when they should be blocked.
Robots Meta Tags vs. Robots.txt
When it comes to controlling how search engine crawlers interact with your website, there are two main tools at your disposal: robots meta tags and robots.txt. While both serve a similar purpose, they differ in their implementation and use cases.

Image courtesy of www.jasonmun.com via Google Images
What is Robots.txt?
The robots.txt file is a text file placed in the root directory of a website that instructs search engine crawlers on which pages they are allowed to access and index. It acts as a gatekeeper, guiding crawlers on how to interact with your site.
When to Use Each
Robots meta tags are typically used on individual web pages to provide specific instructions to search engine crawlers regarding indexing and following links. They allow for more granular control over how each page is treated by search engines.
On the other hand, robots.txt is best utilized for controlling access to entire sections of your website. For example, you may use robots.txt to block crawlers from indexing private or sensitive information on your site, such as admin pages or confidential documents.
Understanding when to use robots meta tags versus robots.txt depends on the level of control you need over how search engines interact with your website. For fine-tuned instructions on a page-by-page basis, robots meta tags are the way to go. If you need broader control over entire sections of your site, robots.txt is the better option.
Frequently Asked Questions (FAQs)
If you don’t use robots meta tags, search engine crawlers may freely access and index all content on your webpage. This can lead to issues such as duplicate content appearing in search results, which can negatively impact your website’s visibility and ranking. Controlling how search engines crawl and index your site is crucial to ensure that your content is properly displayed in search results.
Can I Change Them Later?
Yes, you can change robots meta tags later on. If you realize that you need to adjust how search engine crawlers interact with your webpage, you can go back and update the robots meta tags accordingly. By modifying these tags, you can control which parts of your site are indexed, how often they are crawled, and how they are displayed in search results. It’s important to regularly review and update your robots meta tags to ensure they align with your website’s content and goals.
Want to turn these SEO insights into real results? Seorocket is an all-in-one AI SEO solution that uses the power of AI to analyze your competition and craft high-ranking content.
Seorocket offers a suite of powerful tools, including a Keyword Researcher to find the most profitable keywords, an AI Writer to generate unique and Google-friendly content, and an Automatic Publisher to schedule and publish your content directly to your website. Plus, you’ll get real-time performance tracking so you can see exactly what’s working and make adjustments as needed.
Stop just reading about SEO – take action with Seorocket and skyrocket your search rankings today. Sign up for a free trial and see the difference Seorocket can make for your website!
Summary
In this blog post, we delved into the world of robots meta tags and how they play a crucial role in controlling search engine crawlers as they navigate web pages. Robots meta tags are snippets of code placed within the HTML of a webpage to instruct search engine bots on how to interact with that page.
What Are Robots Meta Tags?
Robots meta tags are essential markers that tell search engine crawlers how to manage the content of a webpage. By placing these tags within the HTML code, website owners can dictate whether a page should be indexed, followed, or cached by search engines.
Why Are They Important?
Robots meta tags are vital for ensuring that search engines interpret and categorize web content correctly. By using these tags effectively, website owners can avoid issues like duplicate content and control the visibility of specific pages in search engine results.
Common Robots Meta Tag Directives
There are several common directives found in robots meta tags, such as ‘index’ and ‘noindex’, which determine whether a page should be included in search engine indexes. Similarly, ‘follow’ and ‘nofollow’ directives control how search engine bots should proceed through linked pages.
Advanced Robots Meta Tag Directives
Advanced directives like ‘noarchive’ and ‘nocache’ offer website owners more nuanced control over how search engines handle their content. These directives allow for specific instructions to be followed regarding content archiving and caching.
When to Use Robots Meta Tags
Relying on robots meta tags can help website owners mitigate duplicate content issues and manage the load generated by search engine crawlers on their site. By strategically implementing these tags, website owners can optimize their site’s visibility and performance in search engine results.
Testing and Verifying Robots Meta Tags
It’s crucial to test and verify that robots meta tags are correctly implemented on a website. Various tools are available to help website owners confirm the functionality of these tags and identify any errors that may be present in their implementation.
Robots Meta Tags vs. Robots.txt
While robots meta tags are embedded within individual web pages, the robots.txt file provides instructions at the website level. Understanding the differences between these two methods can help website owners make informed decisions about how to control search engine crawling on their site.
Frequently Asked Questions (FAQs)
Common questions about robots meta tags include inquiries on the implications of not using them and whether they can be edited after being set. Clear answers to these questions can help website owners navigate the complexities of search engine optimization and ensure their site performs optimally in search results.




