
Unleash the secrets of the digital world with a deep dive into the mysterious realm of the enigmatic crawler.

Image courtesy of via DALL-E 3
Table of Contents
Introduction: Meet the Crawler
Have you ever wondered how search engines like Google find all the information you ask them for? Well, let’s dive into the world of web crawlers to uncover the secret behind this magical process. In this section, we will introduce you to the “crawler” and unveil its role in the vast realm of the internet.
What is a Crawler?
Imagine a special program, like a tiny robot, that scours the web, exploring different websites to gather information. That’s exactly what a crawler does! These little digital helpers, also known as web crawlers, play a crucial role in helping search engines like Google find and organize websites on the internet.
Why are Crawlers Important?
Now, you might be wondering, why do we even need crawlers? Well, these smart programs are essential because they help search engines find new websites, read the content on them, and decide how relevant they are to your search queries. In simpler terms, crawlers make it easier for you to find the information you need on the vast expanse of the internet.
How Crawlers Work
A crawler is like a little explorer that sets out on a big adventure across the internet. It begins its journey by first visiting a list of websites, just like how you start reading a book from the first page.
Following Links
As the crawler visits a webpage, it doesn’t just stop there. It’s curious and wants to learn more, so it follows links that lead to other pages. It’s like going from one room to another in a big house.
Gathering Information
When the crawler lands on a webpage, it doesn’t just admire the view. It looks around carefully, reading and taking notes on what it finds. This information is then collected and brought back to the search engine to help you find what you’re looking for.
The Life of a Web Crawler
Have you ever wondered what the daily routine of a web crawler is like? Let’s take a peek into the fascinating world of these digital creatures that help make the internet work smoothly.
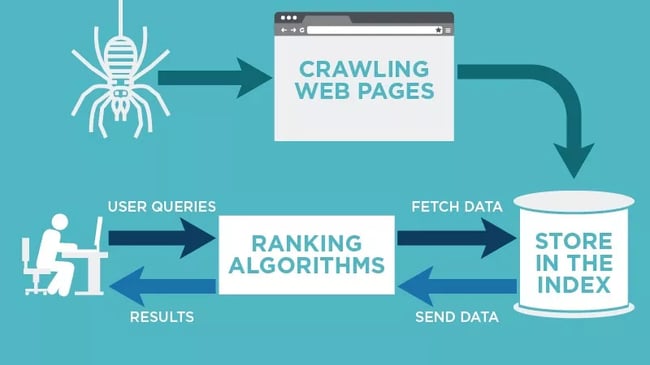
Image courtesy of www.hannonhill.com via Google Images
Robots at Work
Imagine a web crawler as a busy robot tirelessly scanning the vast expanse of the internet. These digital robots start their day by receiving a list of websites to explore from search engines like Google or Bing.
Indexing
As the web crawler visits each website, it carefully collects information like text, images, and links. This data is then organized and stored in a massive database known as an index. This index helps search engines quickly retrieve relevant information in response to user queries.
Regular Updates
Just like you need to regularly update your favorite apps on your phone, web crawlers also go back to websites they’ve previously visited. This ensures that the information provided by search engines is always up-to-date and accurate.
Types of Crawlers
A general web crawler is like a curious explorer that searches all over the internet to find and index different types of information. These crawlers visit websites, scan their content, and store data about them in search engine databases. Imagine them as eager detectives looking for clues to help users find what they’re looking for on the web.
Specialized Crawlers
Specialized crawlers, on the other hand, are like focused experts in a specific field. They delve deep into particular types of information, such as news articles, images, or videos. These crawlers are designed to search and index content that meets a specific criteria, making it easier for search engines to provide users with relevant results based on their search queries.
Challenges Crawlers Face
Web crawlers encounter obstacles when some websites prevent them from accessing their pages. These websites may have security measures in place that block crawlers from exploring and indexing their content. As a result, search engines may struggle to provide up-to-date and comprehensive search results when crucial information is inaccessible to crawlers due to blockages.

Image courtesy of www.dreamstime.com via Google Images
Duplicate Content
Another challenge that crawlers face is dealing with duplicate content scattered across different web pages. When crawlers come across identical or very similar content in multiple locations, they must determine which version is the most relevant to include in search engine results. This task requires advanced algorithms to ensure users receive the most accurate and varied information, rather than seeing the same content repeated in search results.
Crawlers and Privacy
When it comes to privacy concerns surrounding web crawlers, one important aspect to consider is how search engines handle data collection. Search engines have strict policies in place to ensure that data is collected responsibly and ethically. They have guidelines to follow to protect user privacy and ensure that sensitive information is not improperly accessed.
User Information
It’s essential to understand that crawlers may come across user information while exploring the internet. This information may include things like your name, location, or browsing history. However, search engines have measures in place to protect this data and ensure that it is not misused. Your privacy is important, and search engines are committed to safeguarding your information.
The Future of Web Crawlers
In today’s digital world, web crawlers play a crucial role in how we search for information on the internet. As technology continues to advance at a rapid pace, the future of web crawlers holds exciting possibilities for enhancing our online experiences.

Image courtesy of www.octoparse.com via Google Images
AI and Machine Learning
One of the most significant advancements we can expect to see in the future of web crawlers is the integration of artificial intelligence (AI) and machine learning. These technologies have the potential to revolutionize how crawlers gather and interpret data from web pages.
By using AI algorithms, web crawlers can become more intelligent and efficient in recognizing relevant content, filtering out spam, and delivering more accurate search results to users. Machine learning can enable crawlers to adapt and improve their crawling strategies over time, making them even more effective at indexing and ranking web pages.
Speed and Coverage
Another area where we can expect to see advancements in web crawling technology is in speed and coverage. Future web crawlers may be capable of crawling a vast number of websites at faster rates than ever before.
With improved algorithms and infrastructure, web crawlers could cover a wider range of websites in a shorter amount of time, providing users with more up-to-date and comprehensive search results. This increased speed and coverage could make searching the internet even more convenient and efficient for users.
Conclusion: The Power of Crawlers
Throughout this exploration of web crawlers, it has become evident how crucial these specialized programs are in the functioning of the internet. These digital robots tirelessly crawl through the vast expanse of the web, indexing and organizing information to make it easily accessible to users. Let’s recap the essence of crawlers and the impact they have on search engines and the internet as a whole.
Summary of Crawler Importance
A crawler, also known as a spider or bot, is a fundamental tool for search engines like Google to navigate and index the web. They play a pivotal role in ranking websites based on relevance and popularity, ensuring that users receive accurate and valuable search results. Without crawlers, finding information on the internet would be akin to searching for a needle in a haystack. Their ability to gather and categorize data efficiently makes the internet a more user-friendly and organized space.
Role in Search Engines and Internet Accessibility
Crawlers are the unsung heroes behind the scenes, working tirelessly to ensure that search engines like Bing, Yahoo, and others can deliver relevant and up-to-date content to users. By systematically crawling through websites, following links, and gathering information, crawlers enable search engines to provide accurate search results in a matter of seconds. This seamless process of indexing and updating data is what empowers us to explore the vast realm of the internet with ease.
In conclusion, the power of crawlers lies in their ability to organize the chaos of the internet, making it a more navigable and informative space for users around the world. Their relentless efforts in indexing, updating, and categorizing data are the foundation upon which the modern internet thrives. So, the next time you type a query into a search engine and receive instant results, remember to thank the hardworking crawlers that make it all possible!
Want to turn these SEO insights into real results? Seorocket is an all-in-one AI SEO solution that uses the power of AI to analyze your competition and craft high-ranking content.
Seorocket offers a suite of powerful tools, including a Keyword Researcher to find the most profitable keywords, an AI Writer to generate unique and Google-friendly content, and an Automatic Publisher to schedule and publish your content directly to your website. Plus, you’ll get real-time performance tracking so you can see exactly what’s working and make adjustments as needed.
Stop just reading about SEO – take action with Seorocket and skyrocket your search rankings today. Sign up for a free trial and see the difference Seorocket can make for your website!
Frequently Asked Questions
Can Crawlers See Every Website?
Crawlers are pretty amazing at exploring the internet, but they do have some limitations. Some websites can block crawlers from visiting them, so not every single website is accessible to them. This means that while crawlers can see a lot of websites, there are some that they might not be able to visit.
Do Crawlers Make the Internet Work?
Crawlers play a crucial role in helping the internet function smoothly. They are like the helpful detectives that search engines rely on to find and rank websites. While crawlers are important, they are just one part of the internet ecosystem. Many other components work together to make the internet work seamlessly.
How Often Do Crawlers Update Information?
Crawlers work hard to keep the information they find on websites up-to-date. They visit web pages regularly to make sure the content is current. This way, when you search for something on the internet, you get the most recent and relevant results thanks to the efforts of these diligent crawlers.




